Generative AI processes and applications incorporating Generative AI functionality natively rely on accessing Vector Embeddings. This data type provides the semantics necessary for AI to emulate long-term memory processing akin to human capabilities, enabling it to draw upon and recall information for executing complex tasks.
Vector embeddings serve as the fundamental data representation utilized by AI models, including Large Language Models, to make intricate decisions. Similar to human memories, they exhibit complexity, dimensions, patterns, and relationships, all of which must be stored and represented within underlying structures. Consequently, for AI workloads, a purpose-built database, such as a vector database, is essential. This specialized storage system is designed for highly scalable access, specifically tailored for storing and accessing vector embeddings commonly employed in AI and machine learning applications for swift and accurate data retrieval.

A vector database is a database type meticulously crafted for storing and querying high-dimensional vectors. Vectors serve as mathematical representations of objects or data points in a multi-dimensional space, where each dimension corresponds to a specific feature or attribute.
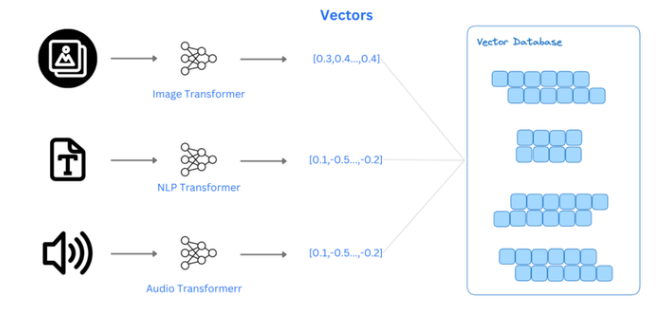


These databases possess the capability to store and retrieve large volumes of data as vectors in a multi-dimensional space, thereby enabling vector search. Vector search, utilized by AI processes, correlates data by comparing the mathematical embeddings or encodings of the data with search parameters, returning results aligned with the query's trajectory.
At the heart of this AI revolution lies Vector Search, also known as nearest neighbor search. This mechanism empowers AI models to locate specific information sets in a collection closely related to a prescribed query. Unlike traditional search models focusing on exact matches, vector search represents data points as vectors with direction and magnitude in a highly-dimensional space. The search assesses similarity by comparing the query vector to possible vector paths traversing all dimensions.
The implementation of a vector search engine represents a significant advancement, facilitating more sophisticated and accurate searches through vast and intricate datasets. Vector search operates by mathematically calculating the distance or similarity between vectors, employing various formulas like cosine similarity or Euclidean distance.
Unlike traditional search algorithms utilizing keywords, word frequency, or word similarity, vector search utilizes the distance representation embedded into dataset vectorization to identify similarity and semantic relationships.
The contextual relevance facilitated by vector search finds application across various domains:
- Similarity Retrieval: Enables applications to adapt to contextual input, facilitating quick identification of variations matching user requirements.


- Content Filtering and Recommendation: Offers a refined approach to filtering content, considering numerous contextual data points to identify additional content with similar attributes.
- Interactive User Experience: Facilitates direct interaction with large datasets, providing users with more relevant results through natural language processing.
- Retrieval Augmented Generation (RAG): Bridges the gap between using data for predicting outcomes and responding to outcomes, augmenting outputs to enhance relevance continually.
Vector search operates by transforming all data into Vector Embeddings. These embeddings serve as mathematical representations of objects, essential for calculating similarity and difference between data points within a multidimensional vector space.
In traditional keyword search, exact results thrive when specific details are known. Conversely, vector search identifies and retrieves semantically similar information, efficiently searching based on similarity rather than exact matches. This capability makes vector search specifically designed for elastically comparing and searching large datasets.

Leveraging vector search offers numerous benefits, including efficient querying and browsing of unstructured data, adding contextual meaning to data using embeddings, providing multidimensional graphical representations of search results, enabling more relevant results based on nearest neighbor search patterns, and enhancing semantic understanding of queries for more accurate results.
The operation of a vector database encompasses indexing, querying, and post-processing stages. Indexing involves encoding information for storage and retrieval, while querying identifies the nearest information to the provided query. Post-processing evaluates the query and returns a final answer by re-ranking the nearest neighbors using different or multiple similarity measurements.

For example:
- Indexing: The term "Orange Signal" on a traffic signal would be indexed differently from the fruit "Orange."
- Querying: Searching for "Orange Signal" on a traffic signal would find similar instances (nearest neighbors) to provide instructions to slow down the vehicle.
- Post-processing: After finding similar instances, the system may provide instructions to stop if the signal converts to red.


No comments:
Post a Comment